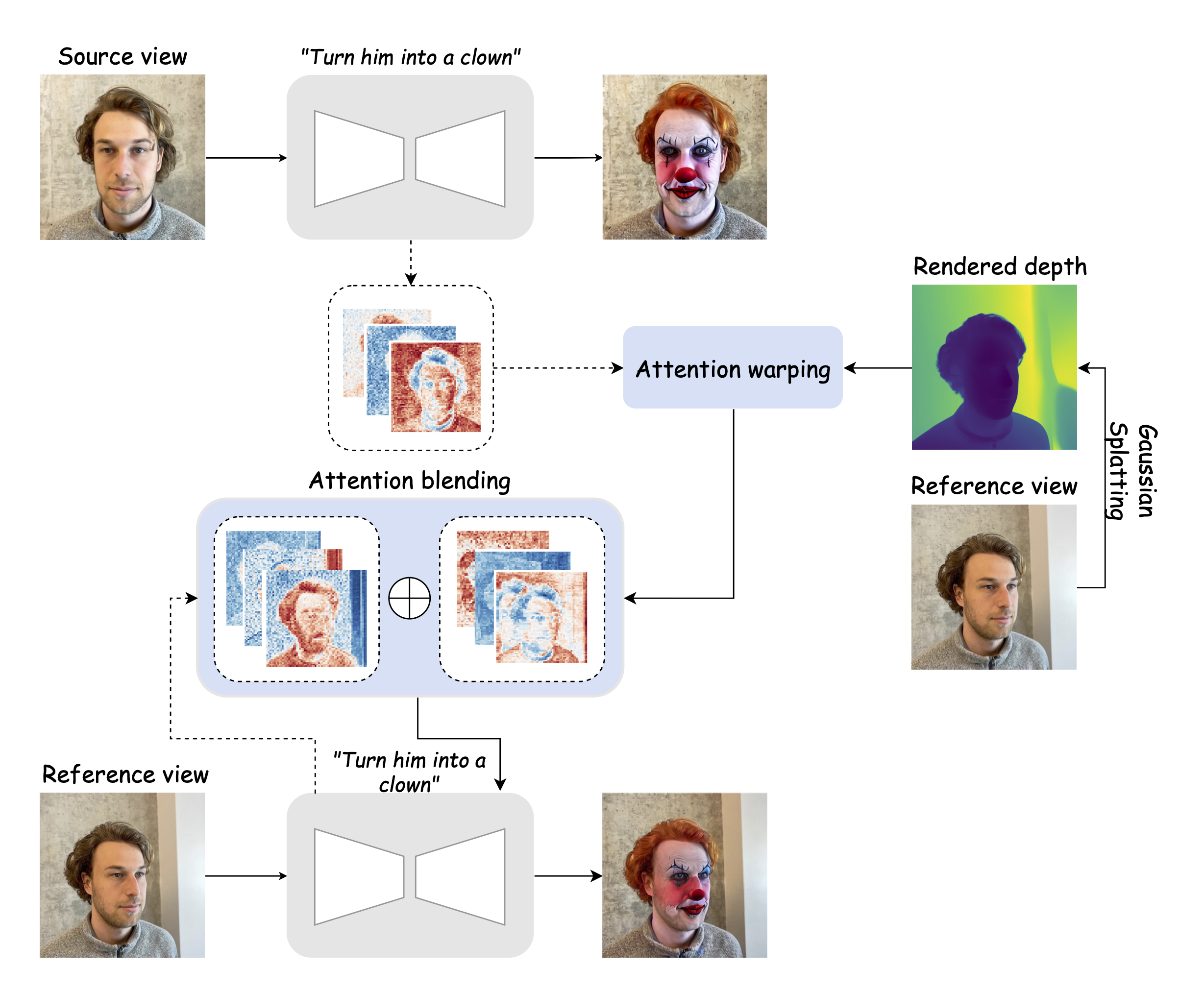
Our method uses 2D diffusion models with attention warping to ensure consistent 3D scene editing. By guiding the process with a single image, we optimize both computational efficiency and memory usage. Starting with a 3D scene represented by a Gaussian splatting model, we apply edits based on textual instructions and a reference image or depth map. We compute attention maps from the source view, then warp them to target views using depth and camera information, ensuring coherence across perspectives. Our approach goes beyond basic 3D scene editing—it allows users to select the style of the edits. Whether using a diffusion model or a non-AI-generated image, users have the flexibility to guide the scene modification in their preferred way. Below is an illustration of the method.